Metric Learning
- Metric Learning - Similarity link
- Metric learning is the task of learning a distance function over objects.
- 객체들 사이의 distance를 학습하는 task
- What " distance function" is?
- A metric or distance function has to obey four axioms(명제): non-negativity, identity of indiscernibles, symmetry and subadditivity (or the triangle inequality).
- Metric learning is the task of learning a distance function over objects.
- Some well-known approaches for metric learning include Learning from relative comparisonswhich is based on the Triplet loss, Large margin nearest neighbor, Information theoretic metric learning (ITML).
- Triplet loss: https://github.com/omoindrot/tensorflow-triplet-loss

Few Shot Learning
Class의 수(N)는 많고 Class별 image의 개수(K)가 적을 때 사용하면 효과적인 방법
https://www.kakaobrain.com/blog/106
Summary
- Metric Learning(거리기반학습)
- Siamese Neural network for one-shot image recognition
- Matching networks for one-shot learning
- Prototypical networks for few-shot learning
- Learning to compare : relation network for few-shot learning
- GNN(그래프 신경망)
퓨샷 러닝이란?
데이터 수가 매우 적은 퓨샷 러닝 문제에서는 데이터셋을 훈련에 사용하는 서포트 데이터(support data)와 테스트에 사용하는 쿼리 데이터(query data)로 구성합니다. 이런 퓨샷 러닝 태스크를 ’N-way K-shot 문제'라고 부릅니다. N은 범주의 수, K는 범주별 서포트 데이터의 수를 의미합니다. 단편적인 예로, [그림 1]처럼 2개의 범주, 범주당 5장의 이미지가 주어진 문제를 2-way 5-shot 문제라고 할 수 있겠습니다.

수백만 장의 고양이 사진을 학습한 딥러닝 모델이 고양이를 명확하게 구분한 예에서 보듯이, K가 많을수록 이 범주에 해당하는 데이터를 예측하는 모델의 성능(추론 정확도)은 높아집니다. 퓨샷 러닝은 이 K가 매우 작은 상황에서의 모델 학습을 가리킵니다. 반면, N의 값이 커질수록 모델 성능은 낮아집니다. 5지 선다형 문제에서 답을 모를 때에는 한 번호만 찍어도 평균 20점을 기대해볼 수 있지만, 100지선다형 문제에서의 기대 성적이 1점이 이 되는 것과 비슷한 원리입니다.
1. 거리 학습 기반 방식
거리 학습(metric learning)과 그래프 신경망(graph neural networks, GNN)
(1) Siamese Neural network for one-shot image recognition

샴 네트워크에서 특징 추출기는 두 개의 입력 데이터 간 거리를 절대적으로 0으로 만들거나 크게 만드는 훈련에 집중합니다.
그러나 이는 테스트 단계에서 주어지는 N-way K-shot 문제를 푸는 데 최적화된 방법론이라고 볼 수는 없습니다.
(2) Matching networks for one-shot learning
따라서 N-way K-shot 문제에서는 데이터 간 상대적 거리를 잘 표현하는 특징 추출기를 만들 필요가 있습니다. 이 논문에서는 최근린 선택기를 미분이 가능한 형태로 제안함으로써 특징 추출기가 스스로 데이터 간 상대적 거리를 표현하는 방법을 익히도록 했습니다. 아울러 N-way K-shot 훈련 태스크에 기반한 에피소딕 훈련 방식을 하는 등 모델의 범주 예측 성능을 높였습니다.
(3) Prototypical networks for few-shot learning
이 논문에서는 범주별 서포트 데이터의 평균 위치인 프로토타입(prototype)이라는 개념을 사용합니다. 결과론적으로 모델은 5개 범주를 대표하는 프로토타입 벡터와 쿼리 벡터와의 거리만 계산하면 됩니다.
저자는 퓨샷 데이터가 주어진 상황에서 프로토타입 네트워크가 Matching networks보다 성능 면에서 더 유리하다고 주장합니다. 쿼리 예측에 필요한 계산량을 N*K에서 N개로 줄이는 한편, 그 구조가 더 단순하다는 걸 근거로 제시하고 있습니다.

(4) Learning to compare : relation network for few-shot learning
하지만 특징 추출기가 같은 범주의 데이터를 더 가깝게, 다른 범주의 데이터를 더 멀게 할 정도로 충분히 복잡하지 않다면 어떨까요? 그렇다면 {러시안블루, 페르시안, 먼치킨}처럼 고양이의 종류를 구분하는 태스크를 풀기 어려울 것입니다.
이 논문에서는 특징 추출기에 CNN을 적용했을 뿐만 아니라 거리 계산 함수에도 다층 퍼셉트론[5]을 적용시켰습니다. 다층 퍼셉트론은 같은 범주 또는 다른 범주의 서포트 데이터와 쿼리 데이터를 분류하는 법을 배웁니다.
2.그래프 신경망 방식
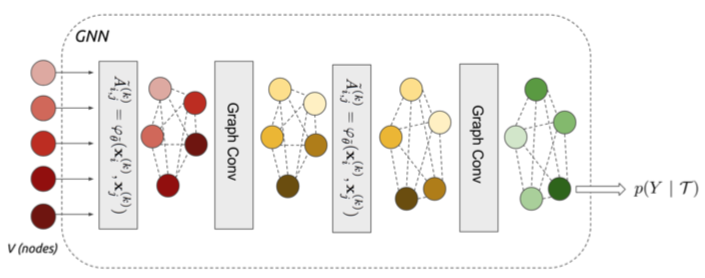
(1) Few-shot learning with graph neural networks
각 노드는 해당하는 데이터의 특징 벡터로 초기화됩니다. 그다음, 특정 노드 V의 이웃 노드에 노드별 거리(유사도)를 곱한 값들의 합(가중평균)을 구합니다. 이를 V와 합쳐 새로운 벡터 V’를 얻습니다. 다른 노드에 대해서도 같은 연산을 순차적으로 반복합니다. 가장 마지막에 쿼리 노드 벡터값의 업데이트도 완료합니다. 모델은 N개의 범주와 완전히 연결된 FC(fully connected layer)층을 통해 쿼리 데이터의 범주를 예측합니다.
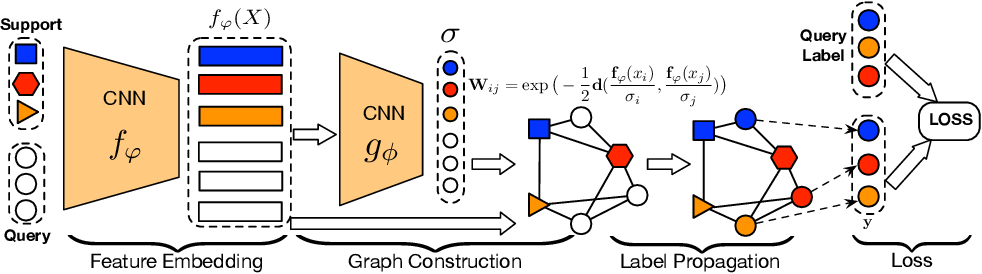
(2) Transductive propagation network for few-shot learning (TPN)
GNN과 다른 점은 노드 값을 초기화한 후 더는 업데이트하지 않는 데 있습니다. 이렇게 되면 범주 정보를 연쇄적으로 전파하는 부분을 하나의 닫힌 형태 방정식(close form equation)으로 표현할 수 있게 됩니다. 이 방식에서는 범주 정보 전파 횟수에 비례해 늘어나는 연산 횟수가 단 한 번으로 줄어 들고, 매 단계에서 얻은 각 노드의 범주 벡터는 메모리에 기록될 필요가 없습니다. 즉, 노드 사이 거리를 고정하면 계산량과 메모리 사용량을 획기적으로 줄일 수 있다는 의미입니다.
TPN은 모든 쿼리 데이터를 학습에 활용함으로써 그 범주를 더 정확하게 예측하게 됩니다. 데이터가 지극히 적은 상황에서 쿼리 데이터도 활용하면 저차원의 매니폴드(manifold)[6] 공간에서 결정 경계(decision boundary)를 더욱 수월하게 찾을 수 있기 때문입니다. 이처럼 라벨링 데이터와 테스트 데이터의 분포를 고려해 테스트 데이터의 범주를 추론하는 방식을 변환 학습(transductive learning)이라고 합니다.
출처: www.kakaobrain.com/blog/106 , github.com/omoindrot/tensorflow-triplet-loss
'DL' 카테고리의 다른 글
| [Python] change even & odd element in 2d list (0) | 2021.03.10 |
|---|---|
| [OpenCV] cv2.addWeighted - Image Overlay (0) | 2021.03.09 |
| [Github] Github CLI: issue create and close (0) | 2021.03.09 |
| [Pytorch] Multi-label classification Loss Selection (0) | 2021.02.22 |
| [딥러닝을 이용한 자연어 처리-조경현] Basic Machine Learning: Supervised Learning (0) | 2021.02.16 |

댓글