Probability 에서 가장 중요한 property 2가지
1. Non-negative: $p(X - e_{i}) \geqq 0$ (특정 event 가 일어날 확률은 0보다 크거나 같다)
2. Unit volume: $ \sum_{e \in \Omega} p(X=e) = 1 $ ( 전체 확률을 모두 더한 값은 1 )
위에서 언급한 확률에서 중요한 2가지 특징을 사용해서 NN에서 예측값으로 사용하기 위해서
Supervised Learning에서 input이 directed acyclic graph를 통과하고 나온 결과가 답을 준다라고 한다.
이것을 input이 주어졌을 때 ouput이 $y'$에 대한 확률이 무었이냐 로 방향을 전환해서 NN을 사용해서 예측하기 위함.
여러 ouput이 존재했을 때 어떤게 likely or unlikely 한가.
Binary Classification - Bernoulli distribution
ouput에 sigmoid function을 적용해서 0~1 사이의 값으로 변환해서 확률을 예측하는 모델로 만들어 주는 것.
x가 주어졌을 때 y가 1일 확률을 return
Multi-class classification - Categorical Distribution
ouput에 exp를 적용해서 non-negative한 값으로 변환하고
그 값을 다 더한 것(Normalization Constant)으로 하나하나 ouput을 나눠준다.
이것이 softmax function인데 이것을 통해 non-negative하고 Unit Vol.=1으로 만들어 주는 것이다.
Loss function - Negative log-probability
conditional distribution과 probability가 NN의 output이라고 했을때,
이제 Loss function을 어떻게 정의할 것인가에 대한 해답이 자연스럽게 주어진다.
Distribution output으로 만듦으로써
Maximum Likelyhood Estimation
Probability를 계산한다고 했을때 실제로 prob를 계산안하고 언제나 log of prob을 계산한다고 생각하면 된다. (추후 설명)
지금 까지는 계속 Maximize에 대해 얘기를 했지만
Loss function으로 적용하려면 minus sign만 붙이면 끝! (Negative log prob) (Minimize 해야되기 때문에)
DAG를 만들고 마지막 끝단에 loss를 넣어주면 끝. pytorch, tensorflow 같은 경우, code reuse도 가능 하고 편리하다.
Optimize the loss function
1. Local, Iterative Optimization: Random Guided Search
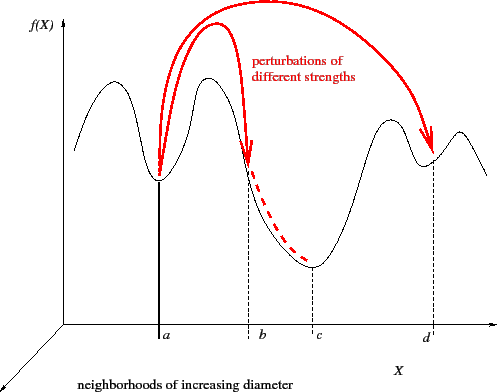
ex. Sampling 100 points in n-dimension space ---> Add noise to each points ---> Find lowest position
---> Sampling 100 points again from the previous position ---> Add noise ---> Find lowest position ---> ... ...
This is efficient way in compact space.
But, in the case of high dimensional space, this is inefficient way. (Curse of dimensionality)
any Loss func 에도 적용이 가능하다
2. Gradient-based Optimization
almost everywhere에 미분이 가능하다고 가정하고
특정 지점에서 loss function의 gradient가 뭔지
어느 방향으로 parameter를 움직여야 값이 작아질지 찾아야.
Learning rate or step size라고 하는 eta parameter를 곱해서 조금만 움직이게해서
어느 쪽으로 가야 값이 떨어진다라고 결정을 하고 그 방향으로 아주 조금만 움직이고
그러면 또 새로운 parameter값이 나오고 그럼 다시 또 반복
위의 random search에 비해서 좋은 점은 계산하는 neighborhood가 작을 순 있지만,
그 작은 neighborhood안에서는 확실하게 방향성을 알려준다.

Backward Computation - Backpropagation
Gradient를 어떻게 계산할 것인가. (수천 수만개의 노드들의 gradient를 어떻게?)
--> Autograd (automatic differentiation)
아무리 복잡해도 composite 하기만 하면 chain rule of derivative를 사용해서 계산이 가능.
각 노드마다 미분을 하는 것을 구현하면 끝에서부터 자동으로 계산
각 노드에서 Jacobian-vector product을 계산합니다.
이 방법 덕분에 네트워크에 구애받지 않고 다양한 시도들이 가능해졌다.
- front-end] 비순환 그래프(DAG)를 만듬으로서 뉴럴넷(모델)을 디자인하는데 집중합니다.
- [back-end] 디자인 된 비순환 그래프(DAG)는 타겟 컴퓨터 장치를 위한 효과적인 코드로 컴파일됩니다. Framework 개발자들이 타겟에 맞춰 알맞게 구현하면 사용자들은 Back-end를 신경쓰지 않고 쓸 수 있습니다.
SGD (Stochastic Gradient Descent)
가정은 "전체 비용은 훈련 샘플의 일부를 선택 후 나눠서 계산한 전체 비용의 근사값(Approximate)와 같다."
SGD는 LR 에 민감합니다. 이를 보완하기 위해서 다양한 Adam, Adadelta 등 다양한 알고리즘이 나왔습니다.
QnA
What is the meaning of stochastic in SGD?
Unlike determinisitc that generates the same result every time, stochastic way is to sample randomly and approximate the result of gradient of all nodes in NN.
For binary classification, what is the difference between using sigmoid VS. softmax (C=2)?
The result is the same.
But, contraint optimizationconstrained optimization, degree of freedom is one.
Output is the same but, gradient could be different.
In function space, both are the same, but parameter space, is not.
What if the examples we select are biased unfortunately, can we still use SGD?
Monte Carlo method or importance sampling
Marginal Probability
the marginal distribution of a subset of a collection of random variables is the probability distribution of the variables contained in the subset. It gives the probabilities of various values of the variables in the subset without reference to the values of the other variables. This contrasts with a conditional distribution, which gives the probabilities contingent upon the values of the other variables. (wikipedia)
조건부 확률과는 대비되는 확률 분포
when to use?
'DL' 카테고리의 다른 글
| [Github] Github CLI: issue create and close (0) | 2021.03.09 |
|---|---|
| [Pytorch] Multi-label classification Loss Selection (0) | 2021.02.22 |
| [Git repo] from "git clone" to "merge" (0) | 2021.01.31 |
| Pytorch Dataset - cv2.imread 메모리 사용 (0) | 2021.01.31 |
| [PUBG] ML_baseline(lightgbm) (0) | 2020.06.02 |


댓글